May 27th, 17 years ago, the first release of WordPress was put into the world by Mike Little and myself. It did not have an installer, upgrades, WYSIWYG editor (or hardly any
Javascript), comment spam protection, clean permalinks, caching, widgets, themes, plugins, business model, or any funding.
…
Seventeen years ago, WordPress was first released.
Sixteen years, eleven months ago, I relaunched I relaunched my then-dormant blog. I considered WordPress/b2/cafelog, but went with a
now-dead engine called Flip instead.
Fifteen years, ten months ago, in response to a technical failure on the server I was using, I lost it all and had to recover my posts from backups. Immediately afterwards, I took the opportunity to redesign my blog and switch to WordPress. On the same day, I attended the graduation ceremony for my first degree (but somehow didn’t think this was worth blogging
about).
Fifteen years, nine months ago, Automattic Inc. was founded to provide managed WordPress hosting services. Some time later, I thought to myself: hey, they seem like a cool company, and
I like everything Matt’s done so far. I should perhaps work there someday.
Ordnance Survey, the national mapping agency for Great Britain, is set to publish revised maps for the whole of the British isles in the wake of social distancing measures. The
new 1:50,000 scale maps are simply a revision of the older 1:25,000 scale map but all geographical features have been moved further apart.
…
Gareth’s providing a daily briefing including all the important things that the government wants you to know about the coronavirus crisis… and a few things that they didn’t think to
tell you, but perhaps they should’ve. Significantly more light-hearted than wherever you’re getting your news from right now.
I walked the dog, bought myself a wax jacket from a local garden centre – so I could feel more ‘Country’ – and in the late afternoon my boss called me to say… you’re fired.
…
So begins Robin‘s latest blog (you may remember I’ve shared, talked about, and contributed to the success of his previous blogging adventure, 52 Reflect). This time around, it sort-of reads like a contemporaneously-written “what I did on my holidays” report, except that it’s pretty-much about the
opposite of a holiday: it chronicles Robin’s adventures in the North of England during these strange times.
I’ve no doubt that this represents the start of another riotous series of posts and perhaps exactly what you need to lift your spirits in these trying times. A second chapter is already online.
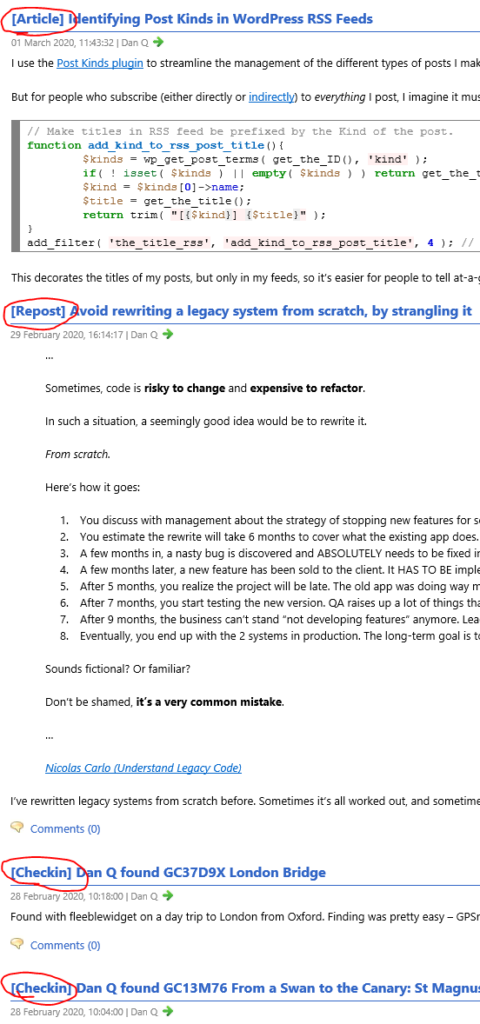
I use the Post Kinds plugin to streamline the management of the different types of posts I make on my blog, based on the
IndieWeb post types list: articles, like this one, are “conventional” blog posts, but I also publish
notes (which are analogous to “tweets”), reposts (“shares” of things I’ve found online, sometimes with commentary), checkins (mostly chronicling my geocaching/geohashing), and others: I’ve extended Post Kinds to facilitate comics and
reviews, for example.
But for people who subscribe (either directly or indirectly) to everything I post, I imagine it must be a little frustrating to sometimes be
unable to identify the type of a post before clicking-through. So I’ve added the following code, which I’m sharing here and on GitHub in case it’s of any use to anybody else, to my theme’s functions.php:
// Make titles in RSS feed be prefixed by the Kind of the post.functionadd_kind_to_rss_post_title(){
$kinds= wp_get_post_terms( get_the_ID(), 'kind' );
if( !isset( $kinds ) ||empty( $kinds ) ) return get_the_title(); // sanity-check.$kind=$kinds[0]->name;
$title= get_the_title();
return trim( "[{$kind}] {$title}" );
}
add_filter( 'the_title_rss', 'add_kind_to_rss_post_title', 4 ); // priority 4 to ensure it happens BEFORE default escaping filters.
This decorates the titles of my posts, but only in my feeds, so it’s easier for people to tell at-a-glance what’s going on:
Down the line I might expand this so that it doesn’t show if the subscriber is, for example, asking only for articles (e.g. via this
feed); I’m coming up with a huge list of things I’d like to do at IndieWebCamp London! But for now, this feels like a nice simple
improvement to a plugin I love that helps it to fit my specific needs.
…why would cookies ever need to work across domains? Authentication, shopping carts and all that good stuff can happen on the same domain. Third-party cookies, on the other hand,
seem custom made for tracking and frankly, not much else.
…
Then there’s third-party JavaScript.
In retrospect, it seems unbelievable that third-party JavaScript is even possible. I mean, putting arbitrary code—that can then inject
even more arbitrary code—onto your website? That seems like a security nightmare!
I imagine if JavaScript were being specced today, it would almost certainly be restricted to the same origin by default.
…
Jeremy hits the nail on the head with third-party cookies and Javascript: if the Web were invented today, there’s no way that these potentially privacy and security-undermining features
would be on by default, globally. I’m not sure that they’d be universally blocked at the browser level as Jeremy suggests, though: the Web has always been about empowering developers,
acting as a playground for experimentation, and third-party stuff does provide benefits: sharing a login across multiple subdomains, for example (which in turn can exist as a
security feature, if different authors get permission to add content to those subdomains).
Instead, then, I imagine that a Web re-invented today would treat third-party content a little like we treat CORS or we’re
beginning to treat resource types specified by Content-Security-Policy and Feature-Policy headers. That is, website owners would need to “opt-in” to which third-party domains could be
trusted to provide content, perhaps subdivided into scripts and cookies. This wouldn’t prohibit trackers, but it would make their use less of an assumed-default (develolpers would have
to truly think about the implications of what they were enabling) and more transparent: it’d be very easy for a browser to list (and optionally block, sandbox, or anonymise) third-party
trackers could potentially target them, on a given site, without having to first evaluate any scripts and their sources.
I was recently inspired by Dave Rupert to remove
Google Analytics from this blog. For a while, there’ll have been no third-party scripts being delivered on this site at all, except through iframes (for video embedding etc., which
is different anyway because there’s significantly less scope leak). Recently, I’ve been experimenting with Jetpack because I get it for free through
my new employer, but I’m always looking for ways to improve how well my site “stands alone”: you can block all third-party resources
and this site should still work just fine (I wonder if I can add a feature to my service worker to allow visitors to control exactly what third party content they’re exposed to?).
Perhaps three people will read this essay, including my parents. Despite that, I feel an immense sense of accomplishment. I’ve been sitting on buses for years, but I have more to
show for my last month of bus rides than the rest of that time combined.
Smartphones, I’ve decided, are not evil. This entire essay was composed on an iPhone. What’s evil is passive consumption, in all its forms.
A side-effect of social media culture (repost, reshare, subscribe, like) is that it’s found perhaps the minimum-effort activity that humans can do that still fulfils our need
to feel like we’ve participated in our society. With one tap we can pass on a meme or a funny photo or an outrageous news story. Or we can give a virtual thumbs-up or a heart on a
friend’s holiday snaps, representing the entirety of our social interactions with them. We’re encouraged to create the smallest, lightest content possible: forty words into a Tweet, a
picture on Instagram that we took seconds ago and might never look at again, on Facebook… whatever Facebook’s for these days. The “new ‘netiquette” is complicated.
I, for one, think it’d be a better world if it saw a greater diversity of online content. Instead of many millions of followers of each of a million content creators, wouldn’t it be
nice to see mere thousands of each of billions? I don’t propose to erode the fame of those who’ve achieved Internet celebrity; but I’d love to migrate towards a culture in which we can
all better support one another’s drive to create original content online. And do so ourselves.
The best time to write on your blog is… well, let’s be honest, it was a decade ago. But the second best time is right now. Or if you’d rather draw, or sing, or dance, or make puzzles or
games or films… do that. The barrier to being a content creator has never been lower: publishing is basically free and virtually any digital medium is accessible from even the
simplest of devices. Go make something, and share it with the world.
For the last few months, I’ve been running an alpha test of an email-based subscription to DanQ.me with a handful of handpicked testers. Now, I’d like to open it up to a slightly larger
beta test group. If you’d like to get the latest from this site directly in your inbox, just provide your email address below:
Subscribe by email!
Who’s this for?
Some people prefer to use their email inbox to subscribe to things. If that’s you: great!
What will I receive?
You’ll get a “daily digest”, no more than once per day, summarising everything I’ve published within the last 24 hours. It usually works: occasionally
but not often it misses things. You can unsubscribe with one click at any time.
How else can I subscribe?
You can still subscribe in a variety of other ways. Personally, I recommend using a feed reader which lets you choose exactly which kinds of content
you’re interested in, but there are plenty of options including Facebook and Twitter (for those of such an inclination).
Didn’t you do this before?
Yes, I ran a “subscribe by email” system back in 2007 but didn’t maintain it. Things might be better this time around. Maybe.
Very occasionally I get asked how to start blogging by people who would like to create exciting and engaging articles that will build a following by delighting an audience hungry
for more. Perhaps they envision spreading their views far across the face of the web.
To which I always reply, “Have you read my blog? I don’t know about any of those things!”
What I do have are 10 years of logs and some vague observations about beginning a blog.
…
As I’m sat here anyway, helping people get started on the Indieweb, here’s a great (tongue in cheek) look at
how you can expect your new blog Indieweb presence to take off and become the Most Popular Thing Ever. Or rather, not.
But as I and others have said before, my blog is first and foremost for me. If you get something out of it too, that’s great, but
that’s a secondary goal!
This adventure took a lot of planning. It’s 350 miles from where I live to Glasgow. I have a Honda CG 125cc, and my maximum range in one day is around 200 miles – if I have the full
day for travelling, which I wouldn’t have, most days. I figured if I was going to have a road trip, I’d have to make stop offs at various parts of the UK, to break it up. This
actually worked out really well, as there are lots of parts of the UK that I wanted to visit.
…
After booking the series of hotel rooms, I started to think about the actual riding. It was two weeks before the trip. I didn’t have enough thermals, or a bike suit that was
protective enough. I also didn’t have a way of storing luggage on my bike, or keeping it dry (and two laptops would be in the bags). There was also an issue with the chain on my
bike that needed fixing. Not exactly a trivial to do list! So the next two weeks turned into a bit of an eBay and Amazon frenzy, with a trip down to see my dad in Kent to get the
bike chain fixed, and rummage around for my old waterproofs in my grandparent’s attic. It was pretty close: the final item arrived the day before the trip. I got ridiculously lucky
on eBay with my new, more visible, better padded, comfy bike suit though, which I love to bits. In hindsight, more time for all of this would have been helpful!
…
My friend Bev wrote about their motorcycling adventure up and down the UK; it’s pretty awesome.
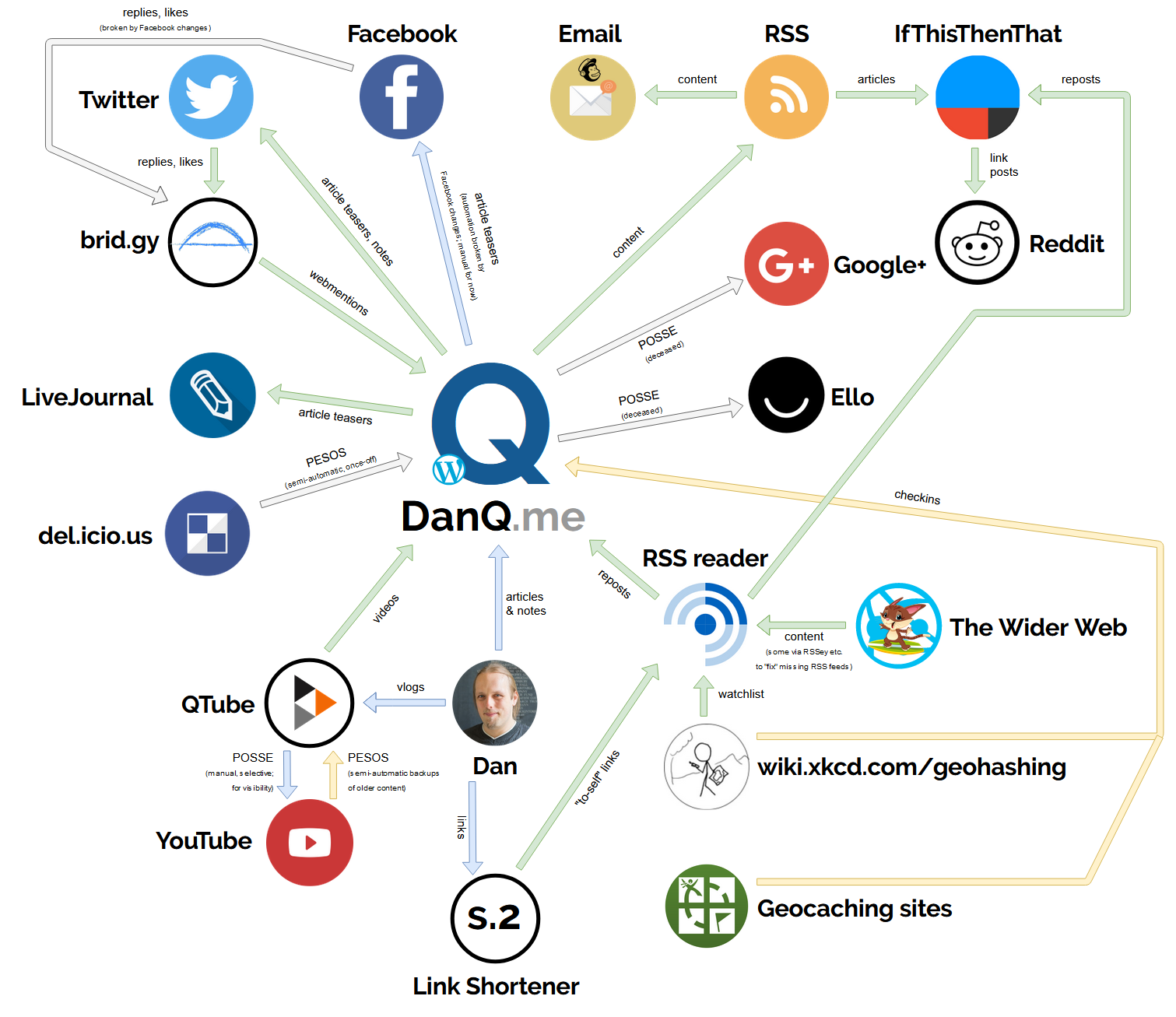
With IndieWebCamp Oxford 2019 scheduled to take place during the
Summer of Hacks, I drew a diagram (click to embiggen) of the current ecosystem that powers and propogates the
content on DanQ.me. It’s mostly for my own benefit – to be able to get a big-picture view of the ways my website talks to the world and plan for what improvements I
might be able to make in the future… but it also works as a vehicle to explain what my personal corner of the IndieWeb does and how it does it.
Here’s a summary:
DanQ.me
Since fifteen years ago today, DanQ.me has been powered by a self-hosted WordPress installation. I
know that WordPress isn’t “hip” on the IndieWeb this week and that if you’re not on the JAMstack you’re yesterday’s news, but at 15 years and counting my
love affair with WordPress has lasted longer than any romantic relationship I’ve ever had with another human being, so I’m sticking with it. What’s cool in Web technologies comes and
goes, but what’s important is solid, dependable tools that do what you need them to, and between WordPress, half a dozen off-the-shelf plugins and about a dozen homemade ones I’ve got
everything I need right here.
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
I write articles (long posts like this) and notes (short, “tweet-like” updates) directly into the site, and just occasionally
other kinds of content. But for the most part, different kinds of content come from different parts of the ecosystem, as described below.
RSS reader
DanQ.me sits at the centre of the diagram, but it’s worth remembering that the diagram is deliberately incomplete: it only contains information flows directly relevant to my blog (and
it doesn’t even contain all of those!). The last time I tried to draw a diagram like this that described my online life in general, then my RSS reader found its way to the centre. Which figures: my RSS reader is usually the first
and often the last place I visit on the Internet, and I’ve worked hard to funnel everything through it.
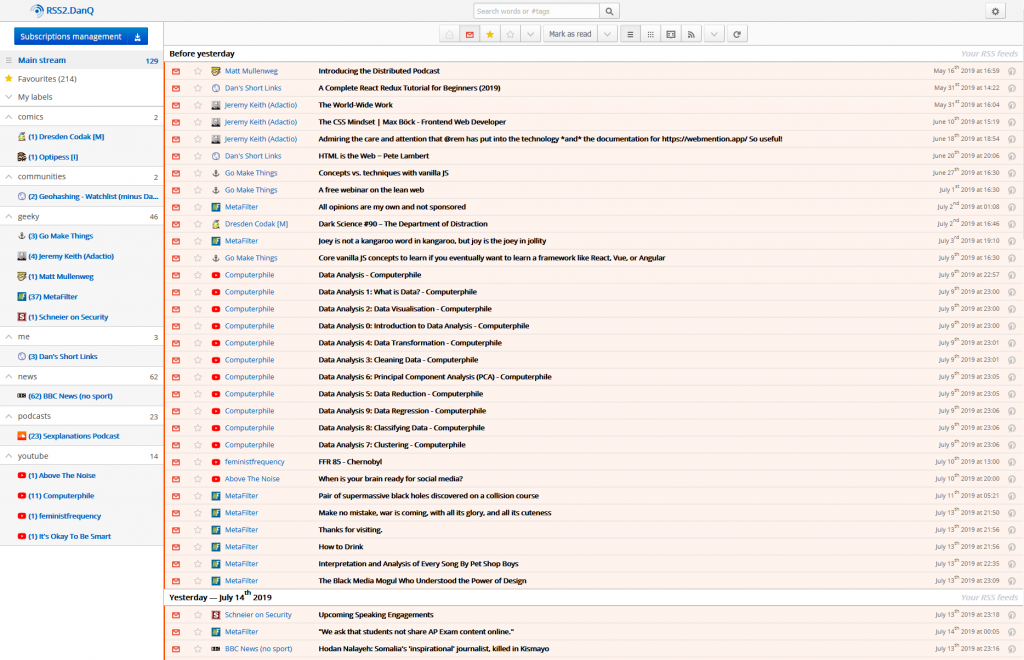
129 unread items is a reasonable-sized queue: I try to process to “RSS zero”, but there are invariably things I want to return to on a second-pass and I’ve not yet reimplemented the
“snooze button” I added to my previous RSS reader.
Right now I’m using FreshRSS – plus a handful of plugins, including some homemade ones – as my RSS reader: I switched from Tiny Tiny RSS about a year ago to take advantage of FreshRSS’s excellent responsive
themes, among other features. Because some websites don’t have RSS feeds, even where they ought to, I use my own tool
RSSey to retroactively “fix” people’s websites for them, dynamically adding feeds for my
consumption. It’s also a nice reminder that open source and remixability were cornerstones of the original Web. My RSS reader
collates information from a variety of sources and additionally gives me a one-click mechanism to push content I enjoy to my blog as a repost.
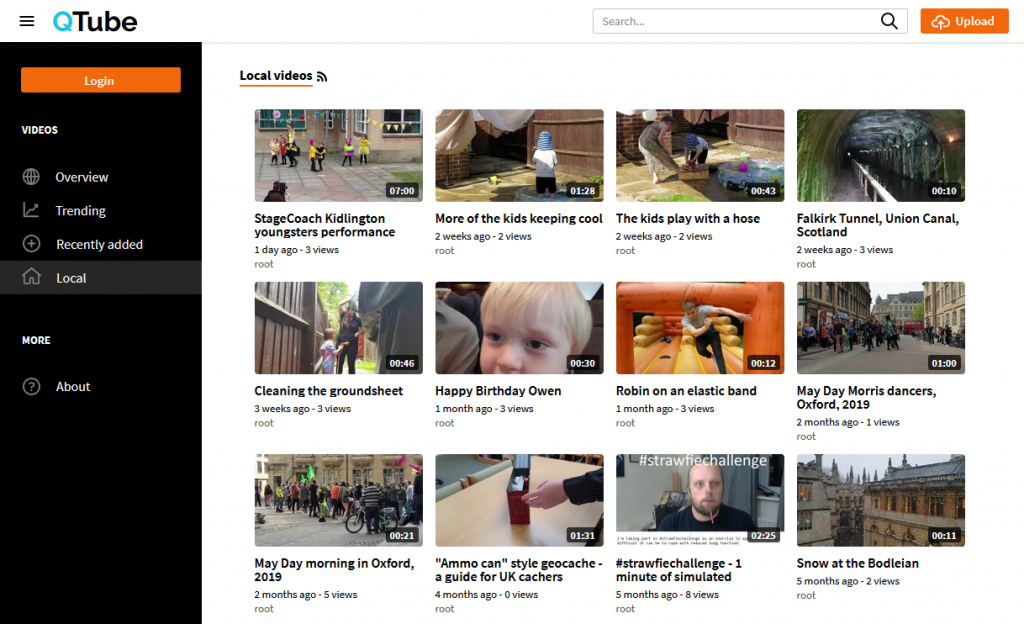
QTube
QTube is my video hosting platform; it’s a PeerTube node. If you haven’t seen it, that’s fine: most content
on it is consumed indirectly either through my YouTube channel or directly on my blog as posts of the “video” kind. Also, I don’t actually vlog very often. When I do publish videos onto QTube, their republication onto YouTube or DanQ.me is optional: sometimes I plan to
use a video inside an article post, for example, and so don’t need to republish it by itself.
I’m gradually exporting or re-uploading my backlog of YouTube videos from my current and previous channels to QTube in an effort to
recentralise and regain control over their hosting, but I’m in no real hurry. PeerTube certainly makes it easy, though!
Link Shortener
I operate a private link shortener which I mostly use for the expected purpose: to make links shorter and so easier to read out and memorise or else to make them take up less space in a
chat window. But soon after I set it up, many years ago, I realised that it could also act as a mechanism to push content to my RSS reader to “read later”. And by the time I’m using it for that, I figured, I might as well also be using it to repost content to my blog
from sources that aren’t things my RSS reader subscribes to. This leads to a process that’s perhaps unnecessarily
complex: if I want to share a link with you as a repost, I’ll push it into my link shortener and mark it as going “to me”, then I’ll tell my RSS reader to push it to my blog and there it’ll be published to the world! But it works and it’s fast enough: I’m not in the habit
of reposting things that are time-critical anyway.
Checkins
You know your sport is fringe when you need to reference another fringe sport to describe it. “Geohashing? It’s… a little like geocaching, but…”
I’ve been involved in brainstorming ways in which the act of finding (or failing to find, etc.) a geocache or reaching (or failing to
reach) a geohashpoint could best be represented as a “checkin“, and last year I open-sourced my plugin for pulling logs (with as much automation as is permitted by the terms of service of some of the
silos involved) from geocaching websites and posting them to WordPress blogs: effectively PESOS-for-geocaching. I’d prefer to be publishing on my own blog in the first instance, but syndicating my adventures from various
silos into my blog is “good enough”.
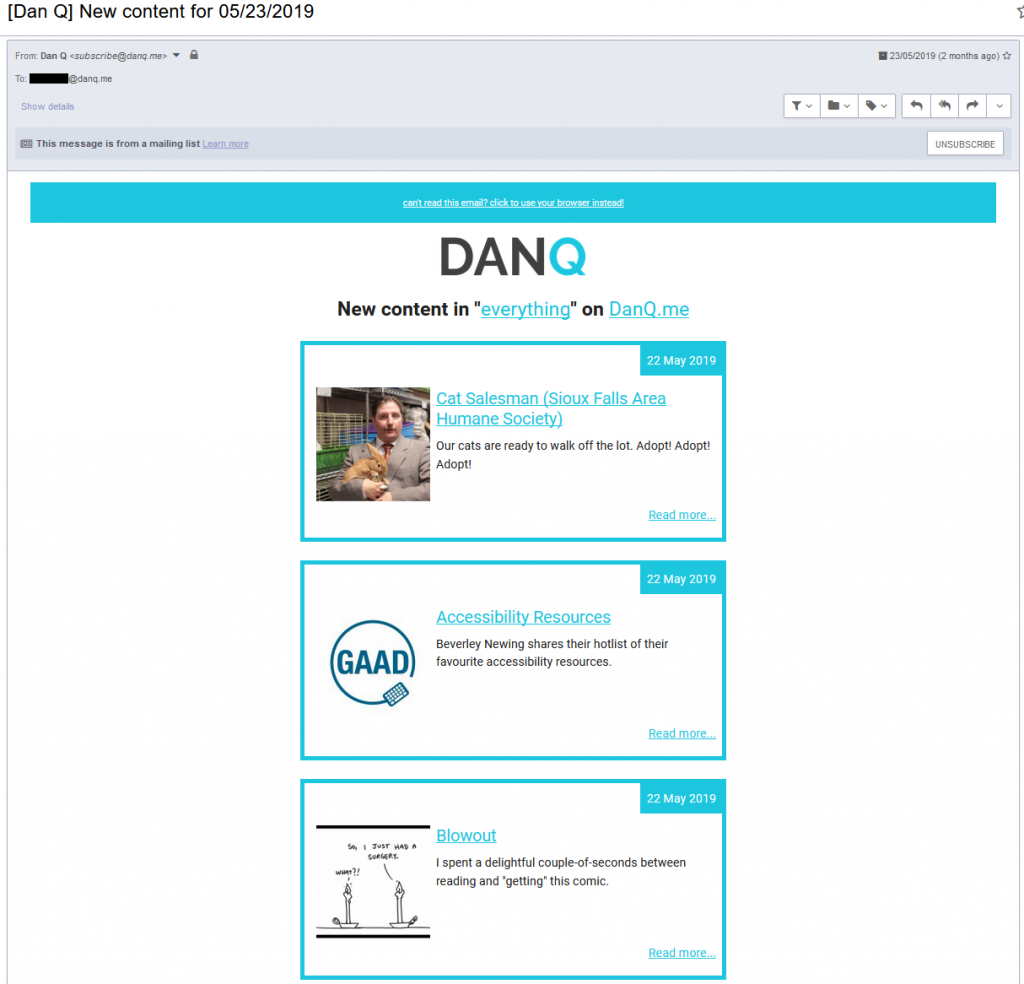
Syndication
New notes get pushed out to my Twitter account, for the benefit of my Twitter-using friends. Articles get advertised on Facebook, Twitter and LiveJournal (yes, really) in teaser form, for the benefit of friends
who prefer to get notifications via those platforms. Facebook have been fucking around with their APIs and terms of
service lately and this is now less-automatic than it used to be, which is a bit of an annoyance. My RSS feeds carry copies
of content out to people who prefer to subscribe via that medium, and I’ve also been using this to power an experimental MailChimp “daily digest” mailing list of “what Dan’s been up to”
to a small number of friends, right in their email inboxes: I’ve not made it available to everybody yet, but if you’re happy to help test it then give me a shout
and I’ll hook you up.
Most days don’t see an email sent or see an email with only one item, but some days – like this one – are busier. I still need to update the brand colours here, too!
Finally, a couple of IFTTT recipes push my articles and my reposts to Reddit communities: I don’t
really use Reddit myself, any more, but I’ve got friends in a few places there who prefer to keep up-to-date with what I’m up to via that medium. For historical reasons, my reposts to
Reddit don’t go directly via my blog’s RSS feeds but “shortcut” directly from my RSS reader: this is suboptimal because I don’t get to tweak post titles for Reddit but it’s not a big deal.
What IFTTT does isn’t magic, but it’s often indistinguishable from it.
I used to syndicate content to Google+ (before it joined the long list of Things Google Have Killed) and to Ello
(but it never got much traction there). I’ve probably historically syndicated to other places too: I’ve certainly manually-republished content to other blogs, from time to time, too.
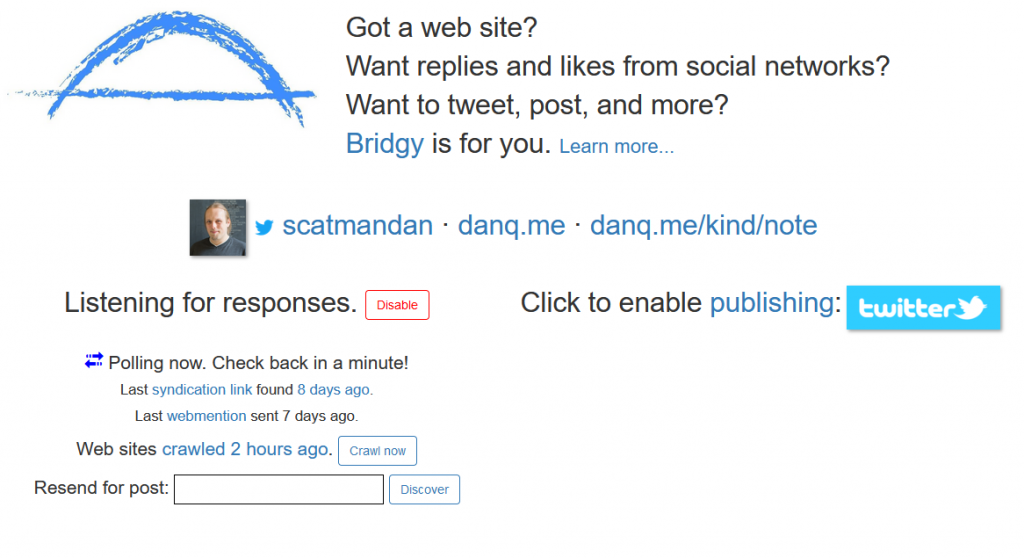
I use Ryan Barrett‘s excellent Brid.gy to convert Twitter replies and likes back into Webmentions for publication as comments on my blog. This used to work for Facebook, too, but again: Facebook
fucked it over. I’ve occasionally manually backfed significant Facebook comments, but it’s not ideal: I might like to look at using similar technologies to RSSey to subvert
Facebook’s limitations.
I’ve never had a need for Brid.gy’s “publishing” (i.e. POSSE) features, but its backfeed features “just work”, and it’s awesome.
Reintegration
I’ve routinely retroactively reintegrated content that I’ve produced elsewhere on the Web. This includes my previous blogs (which is why you can browse my archives, right here on this
site, all the way back to some of the cringeworthy angsty-teenager posts I made in the 1990s) but also some Reddit posts,
some replies originally posted directly to other people’s blogs, all my old del.icio.us bookmarks, long-form forum
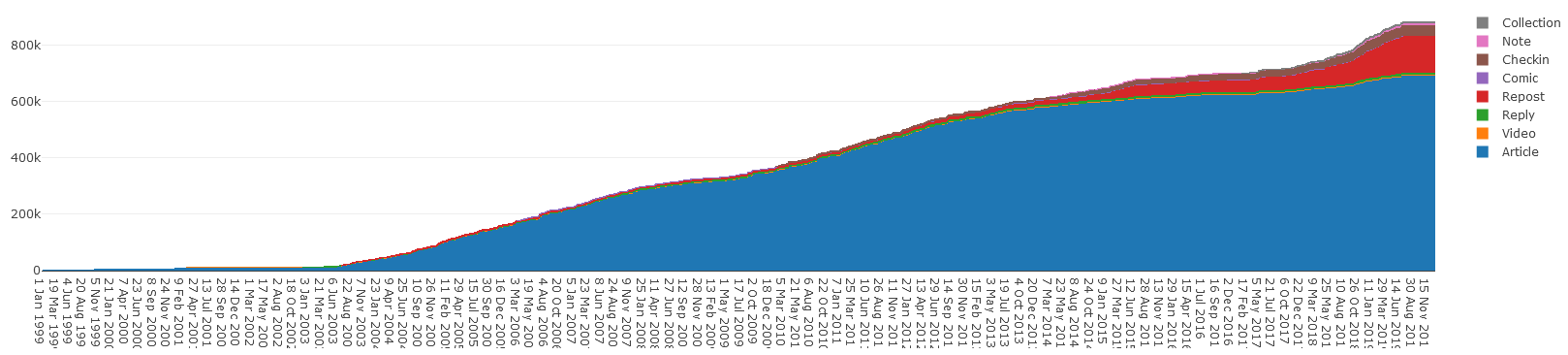
posts, posts I made to mailing lists and newsgroups, and more. As a result, there’s a lot of backdated content on this site, nowadays: almost a million words, and significantly
more than the 600,000 or so I counted a few years ago, before my biggest push for reintegration!
Cumulative wordcount per day, by content type. The lion’s share has always been articles, but reposts are creeping up as I’ve been writing more about the things I reshare, lately.
It’d be interesting to graph the differentiation of this chart to see the periods of my life that I was writing the most: I have a hypothesis, and centralising my own content under my
control makes it easier
Why do I do this? Because I really, really like owning my identity online! I’ve tried the “big” silo alternatives like Facebook, Twitter, Medium, Instagram etc., and they’ve eventually
always lead to disappointment, either because they get shut down or otherwise made-unusable, because
of inappropriately-applied “real names” policies, because they give too much power to
untrustworthy companies, because they impose arbitrary limitations on my content, because they manipulate output
promotion (and exacerbate filter bubbles), or because they make the walls of their walled gardens taller and stop you integrating with them how you used to.
A handful of silos have shown themselves to be more-trustworthy than the average – in particular, eschewing techniques that promote “lock-in” – and I’d love to tell you more about them
and what I think you should look for in a silo, another time. But for now: suffice to say that just like I don’t use YouTube like most people do, I
elect not to use Facebook or Twitter in the conventional ways either. And it’s awesome, thanks.
There are plenty of reasons that people choose to take control of their own Web presence – and everybody who puts content online ought to consider
it – but I imagine that few individuals have such a complicated publishing ecosystem as I do! Now you’ve got a picture of how my digital content production workflow works, and
perhaps start owning your online identity, too.
I would say treat the web like that big red button of the original Flip camera. Just push it, write something and then publish it. It may not be perfect, but nothing ever is anyway.
I write all sorts of crap on my blog — some of it really niche like snippets for Vim. Yet it’s out there just in case someone finds it useful at some point — not least me when I
forget how I’ve done something.
…
I write all kinds of crap on my blog, too, and for mostly the same reasons: my blog is for me, first and foremost. Hopefully others, from time to time, find it
interesting or useful, but I can’t in good faith argue that I keep the shit I wrote in the 90s or early 2000s here for the benefit of the Internet as a whole! It’s for me first.
Good analogy with the Flip camera (follow the link through to Brendan’s post for the full explanation).
When I write a blog post, it generally becomes a static thing: its content always
usually stays the same for the rest of its life (which is, in my case, pretty much forever). But sometimes, I go back and make an
amendment. When I make minor changes that don’t affect the overall meaning of the work, like fixing spelling mistakes and repointing broken links, I just edit the page, but for
more-significant changes I try to make it clear what’s changed and how.
This blog post from 2007, for example, was amended after its publication with the insertion of content at the top and the deletion
of content within.
Historically, I’d usually marked up deletions with the HTML <strike>/<s> elements (or
other visually-similar approaches) and insertions by clearly stating that a change had been made (usually accompanied by the date and/or time of the change), but this isn’t a good
example of semantic code. It also introduces an ambiguity when it clashes with the times I use <s> for comedic effect in the Web equivalent of the old caret-notation joke:
Be nice to this fool^H^H^H^Hgentleman, he's visiting from corporate HQ.
Better, then, to use the <ins> and <del> elements, which were designed for exactly this purpose and even accept attributes to specify the date/time
of the modification and to cite a resource that explains the change, e.g. <ins datetime="2019-05-03T09:00:00+00:00"
cite="https://alices-blog.example.com/2019/05/03/speaking.html">The last speaker slot has now been filled; thanks Alice</ins>. I’ve worked to retroactively add such
semantic markup to my historical posts where possible, but it’ll be an easier task going forwards.
Of course, no browser I’m aware of supports these attributes, which is a pity because the metadata they hold may well have value to a reader. In order to expose them I’ve added a little
bit of CSS that looks a little like this, which makes their details (where available) visible as a sort-of tooltip when hovering
over or tapping on an affected area. Give it a go with the edits at the top of this post!
ins[datetime],del[datetime]{position:relative;}ins[datetime]::before,del[datetime]::before{position:absolute;top:-24px;font-size:12px;color:#fff;border-radius:4px;padding:2px6px;opacity:0;transition:opacity0.25s;
hyphens:none;/* suppresses sitewide line break hyphenation rules */white-space:nowrap;/* suppresses extraneous line breaks in Chrome */}ins[datetime]:hover::before,del[datetime]:hover::before{opacity:0.75;}ins[datetime]::before{content:'inserted 'attr(datetime)''attr(cite);background:#050;/* insertions are white-on-green */}del[datetime]::before{content:'deleted 'attr(datetime)''attr(cite);background:#500;/* deletions are white-on-red */}
CSS facilitating the display of <ins>/<del> datetimes and citations on hover or touch.
I’m aware that the intended use-case of <ins>/<del> is change management, and that the expectation is that the “final” version of a
document wouldn’t be expected to show all of the changes that had been made to it. Such a thing could be simulated, I suppose, by appropriately hiding and styling the
<ins>/<del> blocks on the client-side, and that’s something I might look into in future, but in practice my edits are typically small and rare
enough that nobody would feel inconvenienced by their inclusion/highlighting: after all, nobody’s complained so far and I’ve been doing exactly that, albeit in a non-semantic way, for
many years!
I’m also slightly conscious that my approach to the “tooltip” might cause it to obstruct interactivity with something directly above an insertion or deletion: e.g. making a hyperlink
inaccessible. I’ve tested with a variety of browsers and devices and it doesn’t seem to happen (my line height works in my favour) but it’s something I’ll need to be mindful of if I
change my typographic design significantly in the future.
A final observation: I love the CSS attr() function, and I’ve been using it (and counter()) for all
kinds of interesting things lately, but it annoys me that I can only use it in a content: statement. It’d be amazingly valuable to be able to treat integer-like attribute
values as integers and combine it with a calc() in order to facilitate more-dynamic styling of arbitrary sets of HTML elements. Maybe one day…
For the time being, I’m happy enough with my new insertion/deletion markers. If you’d like to see them in use in their natural environment, see the final paragraph of my 2012 review of The Signal and The Noise.
With 20+ years of kottke.org archives, I’ve been thinking about this issue [continuing to host old content that no longer reflects its authors views] as well. There are many
posts in the archive that I am not proud of. I’ve changed my mind in some cases and no longer hold the views attributed to me in my own words. I was too frequently a young
and impatient asshole, full of himself and knowing it all. I was unaware of my privilege and too frequently assumed things of other people and groups that were incorrect and
insensitive. I’ve amplified people and ideas in the past that I wouldn’t today.
…
Very much this! As another blogger with a 20+ year archive, I often find myself wondering how much of an impression of me is made upon my readers by some of my older posts, and what it
means to retain them versus the possibility – never yet exercised – of deleting them. I certainly have my fair share of posts that don’t represent me well or that are frankly
embarrassing, in hindsight!
I was thinking about this recently while following a thread on BoardGameGeek in which a poster
advocated for the deletion of a controversial article from the site because, as they said:
…people who stumble on our site and see this game listed could get a very (!!!) bad impression of the hobby…
This is a similar concern: a member of an online community is concerned that a particular piece of archived content does not reflect well on them. They don’t see any way in which the
content can be “fixed”, and so they propose that it is removed from the community. Parallels can be drawn to the deletionist faction within Wikipedia (if you didn’t know that Wikipedia had large-scale philosophical
disputes before now, you’re welcome: now go down the meta-wiki rabbit hole).
As for my own blog, I fall on the side of retention: it’s impossible to completely “hide” my past by self-censorship anyway as there’s sufficient archives and metadata to reconstruct
it, and moreover it feels dishonest to try. Instead, though, I do occasionally append rebuttals to older content – where I’ve time! – to help contextualise them and show that they’re
outdated. I’ve even considered partially automating this by e.g. adding a “tag” that I can rapidly apply to older posts that haven’t aged well which would in turn add a disclaimer to
the top of them.
Cool URIs don’t change. But the content behind them can. The fundamental message ought to be preserved, where possible, and so
appending and retaining history seems to be a more-valid approach than wholesale deletion.